DistilBERT
02 Dec 2020제목: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
저자: Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf
발행년도: 2020
DistilBERT는 Hugging Face에서 발표한 pre-train language model로 기존 BERT보다 크기가 40% 작지만 언어 이해 능력은 기존의 97%를 유지하면서 60% 더 빠른 모델이다.
1. Introduction
지난 2년간 NLP task에 사용하는 툴들은 대부분 Transformer를 사용하는 Large-scale pre-trained language model이었는데, 이러한 모델들은 성능 향상은 해주지만 파라미터가 무지 많이 쓰인다.
점점 큰 모델을 학습시키는게 전체적인 성능면에서는 좋은데 단점이 몇 가지 있다.
- environmental cost: 커다란 모델을 학습시키기 위해서 들어가는 에너지 문제
- on-devie & real-time: 실제 기기에서 실시간으로 운영되는 서비스를 만들 때 연산량이나 메모리 크기가 너무 큰 모델은 적용에 어려움이 있을 수 있다.
그래서 이 논문에서 제안하는 바는 더 작은 규모의 pre-trained LM을 사용해서도 큰 모델과 유사한 downstream task 성능을 내고, 더 가볍고 추론도 더 빨리할 수 있으며, pretrain 시키는 연산량도 더 적은 모델을 만들 수 있다. 이 논문에서 제안하는 모델은 충분히 작아서 모바일 기기들에서도 돌릴 수 있을 정도이다.
triple loss를 사용해서 Transformer보다 40% 작고 추론이 60% 빠르다. ablation study를 통해 triple loss를 구성하는 요소들이 모두 중요함을 보인다.
2. Knowledge distillation
Knowledge distillation(지식 증류)이란 일종의 압축 개념인데, 더 작은 모델(학생)이 더 큰 모델(선생, 더 큰 모델 또는 앙상블 모델)의 행동을 재생산할 수 있도록 학습되는 기술을 말한다.
더 나은 이해를 위해 블로그 글을 참고하였다.
Knowledge distillation은 NIPS 2014에 “Distilling the Knowledge in a Neural Network”라는 논문에서 제시된 개념으로, 미리 잘 학습된 큰 네트워크의 지식을 실제로 사용하고자 하는 작은 네트워크에게 전달하는 것이라고 한다. 즉, 작은 네트워크로도 큰 네트워크와 비슷한 성능을 내기 위해 학습과정에서 큰 네트워크의 지식을 작은 네트워크에게 전달해서 작은 네트워크의 성능을 높이는 목적의 기술이다.[1]
지도학습에서 보면 분류 모델은 보통 정답 레이블의 확률을 최대화 시키는 방식으로 학습을 시키기 때문에 예측값과 실제값 사이의 cross-entropy를 최소화 하는 방식으로 학습을 시킨다. 성능이 좋은 모델은 정답 클래스에 높은 확률을, 그리고 다른 클래스들에는 0에 근접한 확률을 예측하는데, 이런 0에 근접한 확률들의 대소관계 또한 학습에 반영된다. (예를들어 고양이 사진의 레이블을 예측할 때 고양이 호랑이 자동차가 있으면 호랑이와 자동차는 정답이 아니니까 0에 근접하게 나오지만, 그럼에도 호랑이의 예측값이 자동차의 예측값보다 클 것이고, 이러한 부분 또한 학습된다는 의미가 있다[2].)
training loss를 계산할 때 soft target probability에 대한 distillation loss를 사용하는데, hard target은 원핫벡터로 주어진 정답에 대한 학습이 이루어지는 것이라면 soft target은 앞에서 말한 확률값을 가지고 학습을 한다. 이 때 아래와 같은 식을 이용한다.
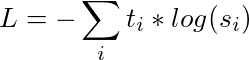
이 방식을 사용하면 더 효율적이고 rich한 학습이 이뤄지는데, 하나의 인풋이 더 많은 정보를 담고 있기 때문이다. 여기에다가 softmax-temperature이라는 것을 사용하는데, 학습시에 선생과 학생 모델 모두에 같은 temperature 파라미터를 적용해주는 것이다. 이를 통해 각 입력에서 더 많은 값들을 학습할 수 있다. 여기서 T 즉 온도는 출력 분포의 부드러운 정도를 조절해주는 값이고, zi는 클래스 i에 대한 model score이다.[3]
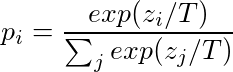
여기에다가 distillation loss와 supervised training loss(MLM loss)를 선형결합해준 값으로 학습을 시켜줬는데, 여기에 cosine embedding loss를 추가해주면 더 학습에 도움이 된다.
3. DistilBERT: a distilled version of BERT
DistilBERT는 knowledge distillation에서 student의 역할을 하는데, BERT의 구조를 사용하지만 token-type embedding과 pooler를 사용하지 않는 구조이며, 레이어의 갯수를 1/2로 줄였다. 또 하나 신경 쓴 부분이 초기화 방법인데, teacher과 student간의 dimensionality가 같다는 것을 활용해서 teacher의 레이어를 1/2개 차출해서 student를 초기화한다.
RoBERTa의 방식을 사용해서 매우 큰 batch와 dynamic masking을 사용하고 next sentence prediction을 사용하지 않는 방식으로 학습되었다. 또한 DistilBERT를 기존의 BERT와 동일한 말뭉치로 학습하였다.
4. Experiments
결과는 GLUE benchmark에 적용하되 검증데이터 성능에 앙상블이나 멀티태스킹을 사용하지 않은 성능을 사용했는데, BERT보다 40% 더 적은 파라미터로 거의 97%의 성능을 내는 것을 확인할 수 있다.
그 외에도 imdb 감성분석이나 SQuAD 등의 downstream task에서도 성능이 BERT보다 낮긴 하지만 파라미터 갯수 대비 매우 높은 성능을 보이는 것을 확인할 수 있다.
여기서 DistilBERT를 한번 더 distil할 수 있는지, 즉 pretraining시 distillation 과정을 거치고 adaptation 단계에서 distillation을 한번 더 시켜본 결과 성능이 크게 낮아지지 않았다.
on-device로 실행해봤을 때 BERT 모델보다 DistilBERT가 71% 더 빨랐다.
5. Related work
관련된 연구로는 Task-specific distillation, Multi-distillation, 그리고 other compression techniques 등이 있다. 관련된 여타의 연구들과 비교해보면 기존 teacher 모델의 지식을 initialization이나 loss 등으로 사용했을 때 성능 향상이 더 크다. (leveraging the teacher’s knowledge leads to substantial gains)
6. Conclusion and future work
결론적으로 이 연구에서는 BERT보다 40% 작고 60% 빠른 DistilBERT를 소개하는데, 이를 통해 범용적인 language model로도 성공적으로 distillation training을 할 수 있다는 것을 보였다. 또한 DistilBERT는 edge application, 휴대폰 등에서 쓰기에 훨씬 매력적인 모델이다.
출처:
[1] 빛나는나무 블로그
[2] DistilBert 리뷰 깃헙 블로그
[3] medium