RoBERTa
16 Nov 2020제목: RoBERTa: A Robustly Optimized BERT Pretraining Approach
저자: Y.Liu et al (UW with Facebook AI)
발행년도: 2019
Language model pretraining을 통해 성능의 향상이 가능하지만, 다양한 접근법 사이의 비교를 하기에는 더 어려워졌다. 또한 학습에 들어가는 연산이 매우 많기 때문에 hyperparameter가 최종 결과에 큰 영향을 미친다.
이 논문에서는 BERT pretraining을 재현하는 시도 중 BERT가 매우 undertrained 되었고, 사실 BERT만 가지고도 이후에 나온 모든 모델들의 성능을 능가할 수 있다고 주장한다. 해당 모델은 GLUE, RACE, 그리고 SQuAD task에 대해 state-of-the-art 결과를 냈으며, 모델과 코드는 https://github.com/pytorch/fairseq 에 올라와있다.
1. Introduction
ELMo, GPT, BERT, XLM, 그리고 XLNet등의 셀프 트레이닝 방식은 눈에 띄는 성능 향상을 이뤘지만, 각각의 모델에서 어떤 요소들이 가장 기여도가 큰지를 결정하기는 어려울 수 있다. 학습을 시키는 데에 연산량이 많이 들기 때문에 튜닝의 횟수도 제한되고, 각 모델별로 다양한 크기의 개인 비공개 데이터를 사용하여 학습을 하기 때문에 modeling advance의 영향을 측정하는 것이 제한된다.
이 연구자들은 BERT를 재현해보다가 BERT가 매우 undertrained 되었다고 판단하여 BERT 모델을 학습시키는 더 개선된 방식을 적용하는 RoBERTa를 제안한다.
RoBERTa가 BERT와 다른 점은 모델을 더 많은 데이터에 대해 더 오래, 더 큰 배치로 학습을 시켰고, next sentence prediction task를 없애고, 더 긴 sequences에 대해 학습하였으며 학습 데이터에 대한 마스킹 패턴이 다이나믹하게 바뀔 수 있게 했다.
또한 CC_NEWS라는 다른 비공개적으로 사용된 데이터셋과 비슷한 크기의 큰 데이터셋을 새로 수집하였고 이를 통해 학습 데이터 크기의 영향을 확인할 수 있었다.
모델을 학습시킨 결과 9개의 GLUE task중 4개 task에 SoTA를 찍었고 SQuAD와 RACE에서도 SoTA를 찍을 수 있었다.
이 논문의 Contribution은 다음과 같다.
- 학습 전략과 BERT design choices를 제안하고 downstream task에 더 좋은 성능을 낼 수 있는 대안 또한 제시한다.
- 새로운 데이터셋인 CC-NEWS 데이터셋을 사용하여 pretrain시 데이터를 더 많이 사용하면 downatream task에 적용했을때 추가적인 성능 향상을 이룰 수 있음을 보인다.
- Masked language model pretraining이 제대로 설계하면 최근에 나온 모델들과 경쟁할만한 성능이 나온다.
코드의 구현은 PyTorch를 사용하였다.
2. Background
BERT의 pretraining 접근법과 학습 방법들에 대해 알아보자.
2.1 Setup
BERT에서 segment는 주로 하나 이상의 자연어 문장으로 이루어져 있는 sequence이다. 여기서 BERT는 두 segment를 [SEP]이라는 구분자를 끼고 concat한 것 앞에 [CLS], 뒤에 [EOS]를 붙인 것을 input으로 받는데 두 시퀀스의 길이의 합이 최대 길이를 넘지 않게 제약조건을 둔다.
모델은 먼저 unlabeled text corpus에 대해 pretrain 되고 이후 end-task labeled data로 finetuning한다.
2.2 Architecture
BERT는 transformer 구조를 사용하는데 레이어의 개수를 L, 셀프 어텐션 헤드의 개수를 A, 그리고 은닉 차원수(hidden dimension)를 H로 두고 사용하였다.
2.3 Training Objectives
BERT를 pretraining 할 때에는 masked language modeling과 next sentence prediction 두 가지 objective를 사용한다.
Masked Language Model (MLM)
입력받은 시퀀스에서 토큰을 랜덤하게 뽑아 [MASK] 토큰으로 대체한다. 이 task의 objective는 masked token을 예측하는 cross-entropy를 줄이는 것이다.
BERT에서는 15%의 토큰을 뽑아서 이 중 80%는 [MASK] 토큰으로, 10%는 그대로, 그리고 10%는 랜덤하게 선택된 단어로 대체한다. 원래 구현에서는 마스킹이 초반에 한번 수행되었지만 실제로는 데이터를 복제해서 매번 다른 토큰을 마스킹한다.
Next Sentence Prediction (NSP)
이 task는 두 세그먼트가 원 텍스트에서 연속적으로 나오는지 예측하는 binary classification을 수행한다. 실제로 연속된 세그먼트인 경우와 연속이 아닌 세그먼트인 경우를 같은 확률로 샘플링한다.
이 task는 문장 쌍의 관계를 추론하는 등의 downstream task에서의 성능을 향상시키기 위해 추가해준 것이다.
2.4 Optimization
BERT는 Adam optimizer를 사용하고 첫 만 스텝에 warm up을, 그리고 모든 레이어에 0.1의 dropout를 사용하고 GELU 활성화함수를 사용한다. 모델은 100만 update동안 학습되며 미니 배치는 최대 512 토큰의 256 시퀀스를 사용한다.
2.5 Data
BERT는 총 16GB의 BOOKCORPUS와 영문 위키피디아 데이터로 학습되었다.
3. Experimental Setup
3.1 Implementation
해당 논문의 저자들은 BERT를 FAIRSEP를 사용하고 재구현하였고, 최적화에 관련해서는 peak learning rate와 warmup steps를 제외하고는 원 BERT 구현과 동일한 hyperparameter를 사용하였다. 그 외에 상황에 따라 Adam optimizer를 살짝 tuning하거나 안정성을 위해 다른 값들도 조금 바꿔주었을 때 더 좋은 성능이 나오기도 하였다.
시퀀스의 최대 토큰 수는 512개로 지정하였고 full-length sequence만 사용하여 학습하였다.
3.2 Data
BERT 방식의 학습은 데이터 규모에 크게 영향을 받는다. 데이터 크기가 클수록 end-task 성능이 높아진다는 연구 결과도 있었다. 실제로 BERT를 더 크고 다양한 데이터로 학습시키려는 시도도 종종 있었는데, 데이터셋은 공개되지 않은 경우도 있었다.
이 연구를 위해 최대한 많은 데이터를 수집하였고, 사용한 데이터는 다음과 같다.
- BOOKCORPUS + English WIKIPEDIA: original BERT data (16GB)
- CC-NEWS: CommonCrawl News dataset의 영어 부분 직접 발췌 (76GB)
- OPENWEBTEXT: Web Text Corpus (38GB)
- STORIES: CommonCrawl data에서 이야기 스타일의 데이터 (31GB)
3.3 Evaluation
기존 BERT 연구와 동일하게 기학습 시킨 모델을 다음의 세 가지 benchmark를 사용하고 평가한다.
- GLUE (General Language Understanding Evaluation): 자연어 이해를 측정할 수 있는 9개의 데이터셋 집합으로 단일문장 분류 또는 문장쌍 분류 task로 이루어져있다. 학습 데이터와 검증 데이터 분할도 되어있고 제출 서버가 있어서 리더보드로 다른 모델들과 성능을 비교할 수도 있다. Section 4에서의 결과는 검증 데이터 기준이며 finetuning은 기존의 BERT와 동일하게 진행하였다. Section 5에서는 public leaderboard 기준의 성능 또한 첨부하였다.
- SQuAD (Stanford Question Answering Dataset): 문맥을 표현하는 문단과 질문을 주면 문맥에서 정답에 해당하는 span을 추출하는 task이다. 이 데이터 셋은 문맥이 언제나 정담을 포함하고 있는 V1.1과 몇몇 문제는 문맥상에서 정답을 찾을 수 없는 V2.0 총 두 가지 버전을 모두 사용하였다. SQuAD V1.1에서는 BERT와 같은 방식을 사용하였고 SQuAD V2.0에서는 질문이 대답할 수 있는 질문인지를 판단하는 이진분류기를 추가해주었다. 그리고 평가시에는 분류 결과 정답이 있다고 분류되는 문제들에 대해서만 정답 span을 예측하도록 하였다.
- RACE (ReAding Comprehension from Examinations): 28000 문단과 거의 10만 개의 질문으로 구성된 대규모의 독해 데이터셋이다. 이는 중국에서 시행되는 영어 시험으로 중고등생 대상이고, 각 문단은 하나 이상의 질문들에 대응된다. task는 4지선다에서 맞는 답 하나를 고르는 것이다. RACE는 다른 독해 데이터셋에 비해 문맥이 특히 더 길고 질문이 요구하는 추론의 정도가 매우 크다는 특징이 있다.
4. Training Procedure Analysis
BERT를 기학습 시키는 데에 어떤 요소들이 중요한지 알기 위해서 먼저 기존 BERT 학습과 동일한 조건으로 학습을 해보았다.
4.1 Static vs. Dynamic Masking
BERT는 masking을 랜덤하게 하여 토큰을 예측함으로써 학습을 하는데, 기존 BERT implementation에서는 데이터 전처리시에 한번 마스킹을 해준다. 우리는 각 epoch마다 마스크를 달리 해주기 위해서 학습 데이터를 10배로 늘려서 각 sequence가 10번의 다른 마스킹이 되도록 해주었고 각 sequence에 같은 마스크를 네번 사용하여 40 epoch으로 학습을 해주었다.
이 방법을 dynamic masking과 비교해보는데, 여기서 dynamic masking이란 각 sequence가 모델에 입력될 때마다 새롭게 마스킹을 해주는 방법이다. 이 방법은 학습을 더 많이 하거나 더 큰 데이터셋으로 학습할 때 더 중요해진다.
각각의 방법을 SQuAD, MNLI-m, SST-2에 적용하여 F1 점수를 비교해본 결과 dynamic masking으로 학습한 모델이 static masking으로 학습한 모델과 기존 BERT모델 상의 정확도보다 모두 더 높거나 비슷한 수준의 성능을 보였고, 이후 실험에도 dynamic masking을 사용하였다.
4.2 Model Input Format and Next Sentence Prediction
기존의 BERT모델에서는 연속된 두 개의 세그먼트를 받아서 해당 세그먼트들이 같은 document에 해당하는지를 예측하는 NextSentence Prediction(NSP) 보조 태스크를 수행한다. 해당 태스크는 학습에 큰 영향을 미친다고 논문에서 소개하였지만 최근 연구에서는 이 NSP 태스크가 꼭 필요하지 않을 수도 있다는 결과들이 있었다.
이를 확인해보기 위해서 몇 가지 학습 형식을 비교해보았다.
- Segment-pair +NSP: 기존의 BERT setting과 동일하다. 두 개의 sequence가 연속으로 나오고 NSP 태스크도 수행하지만 한 입력의 길이가 512 토큰만 넘지 않으면 된다.
- Sentence-pair + NSP: 기존의 BERT setting에서 세그먼트를 문장으로 바꿔준다. 즉 각 입력은 문장쌍으로 이루어져있다. 해당 입력은 512토큰보다 훨씬 작기 때문에 위와 비슷한 학습환경을 위해 batch-size를 키워주었다. NSP 태스크 또한 수행한다.
- Full-sentences: 각 입력은 하나 이상의 document에서 발췌하고 최대 512토큰 길이로 발췌하되 한 document가 끝나고 다음 document가 시작되는 경우 구분자를 추가해주었다. NSP 태스크의 경우 수행하지 않았다.
- Doc-sentences: 입력은 full-sentences와 유사하지만 document의 경계의 경우 다음 document로 넘어가지 않도록 하였고, 이러한 입력의 경우 512토큰보다 짧기 때문에 full-sentences와 비슷한 학습환경을 위해 batch size를 키워주었다. NSP 태스크는 수행하지 않았다.
결과를 비교해보면 NSP 태스크를 수행하는 경우 한 문장씩 샘플링하면 downstream task의 성능이 낮아지는데 이는 long-range dependency가 학습되지 않아서라고 생각한다.
다음으로 NSP를 수행하지 않는 경우와 비교해보면 NSP를 수행하는 경우보다 downstream task 성능이 비슷하거나 더 향상되었다. 특히 doc-sentences가 성능이 조금 더 좋았지만 배치 사이즈가 일정하지 않기 때문에 이후 연구에서는 full-sentences 형식의 입력을 사용하였다.
4.3 Training with large batches
이전 기계 번역 연구들을 보면 큰 규모의 미니 배치로 학습을 할 경우 learning rate를 적절하게 높일 경우 최적화 속도도 빨라지고 end-task 성능도 향상된다는 연구 결과가 있었다. 최근 연구에 따르면 BERT 또한 large batch training을 적용하여 효과를 볼 수 있다고 한다.
기존의 BERT는 256 sequence를 1M step동안 학습했는데, 이는 2K sequence를 125K step으로 학습하는 것, 그리고 8K sequence를 31K step으로 학습하는 것과 연산량이 동등하다.
각각의 경우로 학습을 시켜본 결과 더 큰 배치로 학습시킬 때 perplexity가 개선되고 end-task accuracy또한 개선되는 것을 확인할 수 있다. 또한 큰 배치는 병렬로 학습을 시키기에도 더 쉽다.
이후 실험에서는 8K sequences 배치로 학습을 하였다.
4.4 Text Encoding
Byte-Pair Encoding은 character-level과 word-level representation을 모두 사용하는 방식이다. BPE는 subword 단위를 사용하는데, 이는 학습 말뭉치에서 통계적 분석을 통해 추출한다.
BPE vocabulary의 크기는 10K ~ 100K 사이인데 유니코드 캐릭터가 많은 공간을 차지하기 때문에 bytes를 사용하는 연구 또한 시도되었다. 이를 통해 약 50K의 unit으로 unknown token 사용 없이도 어떠한 입력도 처리하는 것이 가능해졌다.
기존의 BERT implementation에서는 vocab size가 30K인 character-level vocabulary를 사용하였지만 이 연구에서는 50K sub-wrod unit의 byte-level BPE vocabulary를 사용하였다. 초기 연구에서는 이러한 인코딩의 차이로 인한 성능의 차이가 거의 없었지만 모든 인풋을 처리할 수 있다는 것이 성능이 조금 낮아지는 것보다 더 이득이라고 생각했기 때문에 이후 연구에서는 50K byte-level encoding 방식을 사용하였다.
5. RoBERTa
이전에 알아본 end-task performance를 개선할 수 있는 요소들을 모아서 성능을 측정해볼 것인데, 이를 Robustly optimized BERT approach를 줄여 RoBERTa라고 부른다. RoBERTa는 dynamic masking, FULL-SENTENCES without NSP loss, large mini-batches, larger byte-level BPE를 사용한다.
여기에서 BERT 논문에서 덜 고려되었다고 생각하는 두 가지 요소를 추가하는데 이는 pretraining 데이터 크기와 학습 정도이다. 먼저 BERT LARGE 구조와 동일한 크기의 모델을 비슷한 크기의 데이터셋인 BOOK-CORPUS + WIKIPEDIA 데이터셋에 100K step동안 학습을 시키고 이후 데이터셋을 추가하고 학습 step 수를 늘리는 등으로 확장해나갔다.
Result
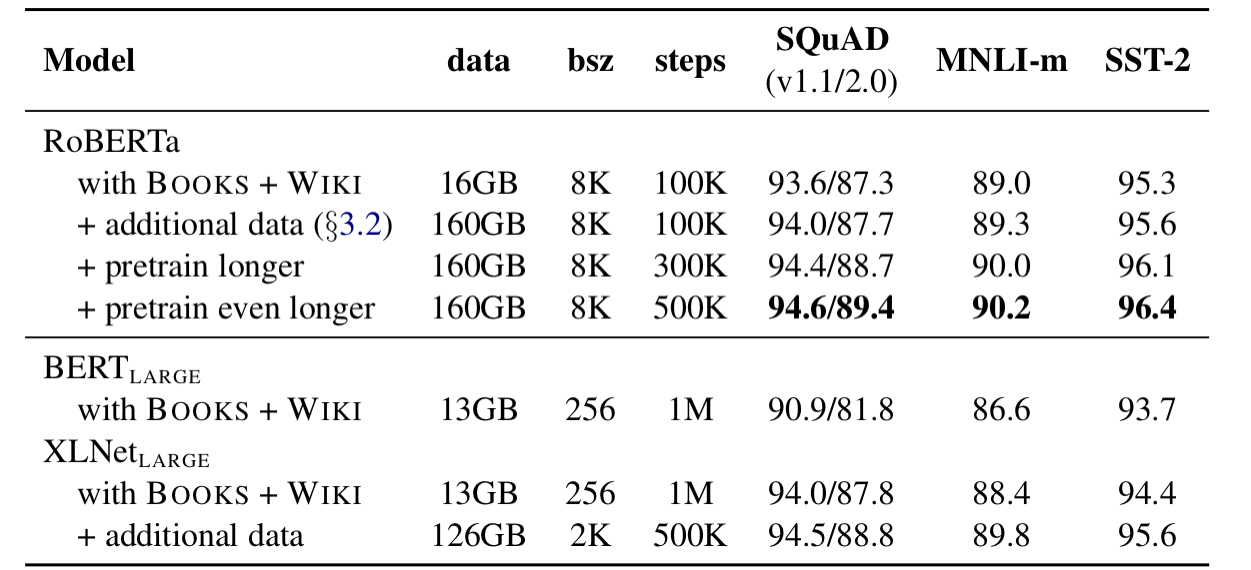
위 표를 보면 추가적인 데이터셋 없이 학습을 시킨 결과만 보아도 기존의 BERT LARGE 모델보다 downstream task의 성능이 더 뛰어난 것을 확인할 수 있다.
여기서 앞에서 언급했던 추가적인 데이터셋 세개를 추가하여 학습을 시켜주었다. 데이터셋만 추가해주고 같은 step만큼 학습을 시켜줬을 때 추가적으로 성능이 더 좋아지는 것을 확인할 수 있다.
마지막으로 pretraining step 수를 300K, 그리고 500K로 늘려 학습을 시켜본 결과 XLNet LARGE 모델보다도 성능이 비슷하거나 더 좋은 결과를 얻을 수 있었다.
이후 결과에서 가장 좋은 성능이 나온 RoBERTa 모델(500K steps, all 5 datasets)을 GLUE, SQuAD, RACE benchmark에 적용해볼 것이다.
5.1 GLUE Results
GLUE에서는 두 가지 finetuning setting이 있는데, single-task finetuning에서는 RoBERTa를 각각의 GLUE task에 대해서 해당 task에 해당하는 training data만 사용해서 finetuning 시켰고 hyperparameter를 찾아주었다. 결과는 다섯번의 랜덤 초기화의 중간값을 사용하였다. 두 번째는 ensemble 방식으로 GLUE leaderboard에 올리는 test set에 모델을 적용하는 것이다. 많은 제출물들이 multitask finetuning을 사용했지만 RoBERTa는 single-task finetuning만을 사용했다.
GLUE task중 QNLI와 WNLI는 추가적인 finetuning이 필요했는데, QNLI의 경우 ranking approach를 적용을 시도했지만 BERT와의 비교를 위해 classification 접근의 결과를 report 하였다. WNLI의 경우 제공된 NLI 형식의 데이터는 사용하기가 어려워서 Super-GLUE의 reformatted WNLI 데이터를 사용하였다. margin ranking loss와 spaCy를 사용하여 모델을 finetuning 해서 긍정적인 referent phrase에 더 높은 점수를 주게 하였다.
결과적으로 single-task single models에서는 모든 task에 SoTA를 찍었고, ensemble setting에서도 9개 중 4개의 데이터셋에 대해서 SoTA 성능을 냈고, 평균점수 또한 현재까지 가장 높다.
5.2 SQuAD Results
SQuAD 데이터셋에 대해서는 RoBERTa를 제공된 SQuAD 학습 데이터로 finetuning만 해주었다. SQuAD v1.1에서는 BERT와 동일한 finetuning을 해주었고 SQuAD v2.0에서는 질문을 입력받았을 때 이 것이 대답할 수 있는 질문인지 구분하는 classifier를 같이 학습시켜주었다.
결과를 보면 SQuAD v1.1에서는 XLNet과 유사한 정도의 성능을 내었고, SQuAD v2.0에서는 아예 새 SoTA 성능을 찍었다. public SQuAD 2.0 leaderboard에도 제출을 한 결과 추가적인 데이터를 사용하지 않고 data augmentation을 사용하지 않는 모델들 중에서 성능이 가장 높은 축에 속한다.
5.3 RACE Results
RACE에서는 긴 지문에 질문과 선지 4개가 주어진다. 이를 위해 RoBERTa에 정답 후보와 질문, 그리고 지문을 concatenate해서 인코딩해서 나온 [CLS] 토큰을 완전연결망에 통과시켜 정답을 예측할 수 있게 하였다.
결과적으로 중학교 수준과 고등학교 수준 모두에서 SoTA 성능을 낼 수 있었다.
6. Related Work
Pretraining model들은 다양한 학습 목표를 가지고 설계되었었고 최근 연구에서는 finetuning을 위해 기본적인 recipe를 사용하거나 masked language model을 살짝 변형하여 pretraining을 하는 경우가 많았다. 더 최근에 연구된 방법들에서는 multi-task finetuning을 사용하여 성능을 향상시켰고, 또한 더 큰 모델을 더 많은 데이터로 학습시켜서 성능을 향상시키는 경향이 있다.
해당 논문의 목적은 이러한 최근 성능 향상에 기여하는 방법들을 더 잘 이해하기 위해 BERT를 재현하고 더 간단히, 다양한 방법으로 더 잘 튜닝해보는 것이었다.
7. Conclusion
이 연구를 통해 모델을 더 오래, 더 큰 배치에 학습시키면 성능이 향상된다는 것을 알 수 있었고, 그 외에도 next sentence prediction을 하지 않고, 더 긴 sequence로 학습하고 또 masking pattern을 dynamic하게 바꿔주는 것이 성능 향상에 기여한다는 것을 확인할 수 있었다.
이 RoBERTa라는 모델은 GLUE에서는 multi-task finetuning을 사용하지 않고 SQuAD에서는 추가적은 데이터를 사용하지 않았음에도 GLUE, RACE, SQuAD에서 SoTA를 냈다.
이 연구를 통해 BERT를 만들때 덜 고려된 방법들의 중요성과, BERT의 pretraining 방법이 최근 제안된 대안들과 충분히 견줄만 하다는 것을 보였다.
추가적으로 해당 연구에서는 이전에 사용된 바 없는 CC-NEWS 데이터셋을 사용하였고, RoBERTa 모델에 관련된 코드는 <a href=”https://github.com/pytorch/fairseq”>https://github.com/pytorch/fairseq</a>에서 확인할 수 있다.