TRANSFORMER
07 Sep 2020Transformer란?
2017년 NIPS에 게재된 “Attention is All You Need”라는 논문에서 처음 제안된 모델로, attention을 사용한 encoder-decoder 모델의 일종이다.
encoder-decoder 모델
encoder-decoder 모델은 sequence-to-sequence(seq2seq) 학습모델 중 대표적인 모델인데, seq2seq는 이름에서 알 수 있듯, 입력 시퀀스를 통해 다른 도메인의 시퀀스를 출력하는 모델이다[1]. encoder에서는 입력받은 소스 데이터를 압축하고 decoder에서는 encoder가 압축하여 보내준 정보를 타겟 데이터로 변환하여 출력을 해준다[2]. Encoder-decoder 모델이 사용되는 예시로는 한 언어에서 다른 언어로 문장을 번역하는 translation task나 text summarization, image captioning, conversational modeling 등이 있다[3].
이제 기존의 encoder-decoder 모델에서는 RNN, LSTM, GRU등을 사용을 해왔는데 LSTM과 GRU도 사실상 RNN의 일종이다. RNN 모델에는 약간의 한계점들이 존재하는데,
- 문장의 길이가 길어질수록 닾의 단어가 뒤의 단어에 주는 영향이 작아진다. 즉, 단어간 거리가 멀어질수록 문맥정보를 학습하기 어렵다.
- RNN은 일방향으로만 학습이 이루어지기 때문에 뒤에 나온 단어가 앞에 나온 단어에 영향을 미치지 못한다.
이러한 한계점을 해결하기 위해 양방향으로 학습이 이루어지는 bidirectional RNN 모델도 등장하였다.
Attention
우리가 수능특강 영어 영역 문제를 풀 때 문단 내 어떤 단어의 뜻을 알기 위해 주변 단어들에 더 관심을 두며 지문을 읽으면 더 효과적으로 문제를 해결할 수 있다. 이처럼 우리는 어떤 특정한 목적을 가지고 읽을 때 모든 단어에 같은 정도의 관심을 주지는 않는다. 이와 유사하게 어떤 특정한 기준에 따라 입력된 각각의 토큰들에 대한 가중치(attention)을 조절해주는 방식으로 학습을 해주는 방법이 있다. 이를 seq2seq 모델에 적용을 하면 각 timestep에 모든 입력받은 토큰들에 대한 attention값들이 달라진다.
Attention은 Query, Key, Value 이렇게 세개의 값을 가지고 계산을 하는데, query, key, value는 쉽게 생각하면 유튜브에서 동영상을 검색할 때, 내가 입력한 값이 query, 동영상의 제목이나 설명 등 그 동영상을 특정할 수 있는 값이 key, 그리고 검색 결과에 해당하는 동영상이 value라고 비유할 수 있다[4].
이제 위의 정보들을 가지고 Transformer 모델에 대해 알아보자.
Transformer 모델
Transformer 모델의 구조는 다음과 같다.
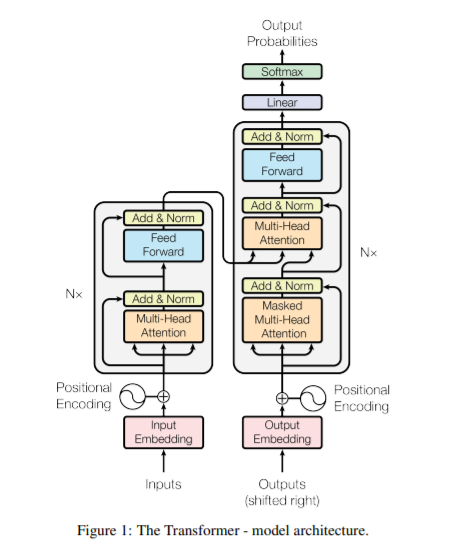
기본적으로 Encoder와 Decoder로 이루어져 있다.
- Encoder: 동일한 encoder 레이어 6층으로 이루어져 있으며 각 레이어는 두 개의 하위 레이어(multi-head attention, feed-forward)로 이루어져 있다. output의 dimension은 dmodel=512로 통일한다.
- Decoder: 동일한 decoder 레이어 6층으로 이루어져 있으며 각 레이어는 인코더의 두 개의 하위 레이어에 추가적으로 encoder의 출력에 대한 multi-head attention을 수행하는 하나의 하위 레이어가 추가된다. 또한, self-attention을 변형하여 현재 위치에서 알 수 있는 정보들만 가지고 학습이 이루어질 수 있도록 마스킹을 한다.
Attention 함수는 query를 key-value쌍 집합에 매핑해준다고 생각하면 되는데, 이 때 query, key, value 그리고 output이 모두 vector이다. 출력의 경우 value의 가중치합으로 계산된다. (위에서 좀 더 자세히 설명해두었다.) Transformer에서는 이러한 attention 함수 중에서도 Scaled Dot-Product Attention을 사용하는데 이는 query를 모든 key와 dot product 해준 후 이를 √dk로 각각 나눠준 뒤 softmax를 사용하여 값을 얻는다.
Multihead attention부터 이어서 작성 예정
출처:
[1] 딥 러닝을 이용한 자연어처리 입문 (https://wikidocs.net/24996)
[2] ratsgo님 블로그 (https://ratsgo.github.io/natural%20language%20processing/2017/03/12/s2s/)
[3] nlp-bert-transformer (https://medium.com/@jonathan_hui/nlp-bert-transformer-7f0ac397f524)
[4] stackexchange most voted answer (https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanisms)