BERT
04 Sep 2020BERT란?
2019년 NAACL에 게재된 “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”이라는 논문에서 제안된 모델이다. BERT는 Bidirectional Encoder Representations from Transformers의 줄임말로, 언어표현모델(language representation model), 정확히 말하면 학습 방법의 일종이다[1].
BERT 모델은 unlabeled text들로부터 deep bidirectional representation을 pre-train할 수 있고, 하나의 추가적인 output layer을 통해 sentence-level task부터 token-level tasks 등 다양한 nlp task에 적용할 수 있다. 이런 sentence-level task나 token-level task, 더 자세히는 question answering task, language inference task등 구체적으로 풀고 싶은 문제들을 downstream task라고 한다[3].
pre-trained language representation을 이러한 downstream task에 적용하는 방법은 feature-based approach와 fine-tuning approach으로 크게 두 가지가 있는데, ELMo의 경우 feature-based 방식을 사용하고 Generative Pre-trained Transformer(GPT) 모델의 경우 fine-tuning 방식을 사용한다. BERT는 feature-based 방식과 fine-tuning 방식 모두 사용 가능하지만 논문에서는 fine-tuning based approach를 중심으로 소개한다.
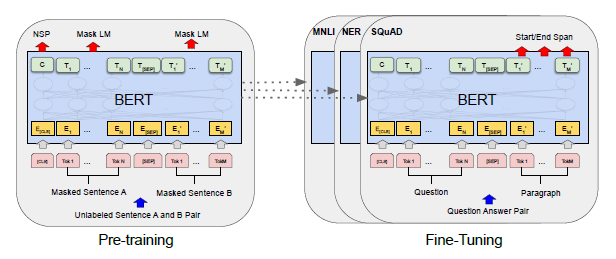
Model Architecture
BERT는 transformer의 encoder를 활용한 모델인데(transformer에 대한 내용은 TRANSFORMER에 대해 알아보자 를 참고하자), transformer 모델에서는 attention head가 8개인 동일한 encoder layer 6층이 하나의 encoder로 사용되었던 반면 BERT는 base 모델 기준 attention head 12개, encoder layer 12층으로 이루어져있다.
BERT의 input은 WordPiece embedding을 사용하고, sequence(여기서 sequence는 input token sequence를 의미하는데 하나의 문장일수도 있고 둘 이상의 문장일수도 있다)의 시작부에 [CLS] 토큰을, 그리고 문장과 문장 사이에는 [SEP] 토큰을 추가해준다.
BERT는 크게 두 가지 task를 통해 pre-train이 이루어지는데, 첫 번째 task는 Masked Language Model(MLM) task이고, 두 번째 task는 next sentence prediction task이다.
1. Masked Language Model (MLM)
MLM task는 BERT 모델에서 입력받은 token들의 일부(논문에서는 15%)를 랜덤하게 masking하고 해당 masked token들을 예측하는 task인데, 이를 통해 bidirectional pre-trained model을 얻을 수 있다.
여기서 training 할 때에는 mask 토큰을 사용해줬는데 이후 fine-tuning시에서는 mask 토큰을 사용하지 않기 때문에 mismatch가 나타날 수 있다. 이를 위해 BERT 모델은 masking할 15%의 토큰중에서 80%는 mask 토큰으로 대체, 10%는 랜덤한 토큰으로 대체, 그리고 나머지 10%는 원래 토큰을 그대로 사용하여 학습을 진행하였다.
2. Next Sentence Prediction (NSP)
NSP task는 문장쌍을 입력을 받아서 두 문장이 이어지는 문장인지를 판단하는 task이다. 이 때 50%는 실제 이어지는 문장쌍을, 50%는 두번째 문장을 corpus에 존재하는 랜덤한 문장으로 넣어준 문장쌍을 가지고 학습을 한다. 이때 두 문장이 이어지는지는 softmax를 가지고 계산을 한다.
이후 연구들에서 NSP는 실제로 크게 효과가 없다는 의견이 나오기도 했다.
Fine-tuning
fine-tuning approach는 downstream task 학습시 기존에 학습시킨 파라미터들을 전부 다시 학습을 시키는 방법이다. 하지만 pre-train시 방대한 양의 dataset으로 이미 한 번 학습을 시켰기 때문에 매번 train하는것보다 한 번 pre-train 하고 fine-tuning을 하는 것이 연산 측면에서 더 효율적이다.
논문에서는 fine-tuning시 batch size, learning rate, training epochs를 제외한 hyper parameter들은 pre-training때와 동일하게 설정을 해주었고, output단에 classification layer를 한 층 추가하여 softmax로 계산한 label probabilities를 통해 fine-tuning의 결과를 얻을 수 있는 방식으로 진행하였다.
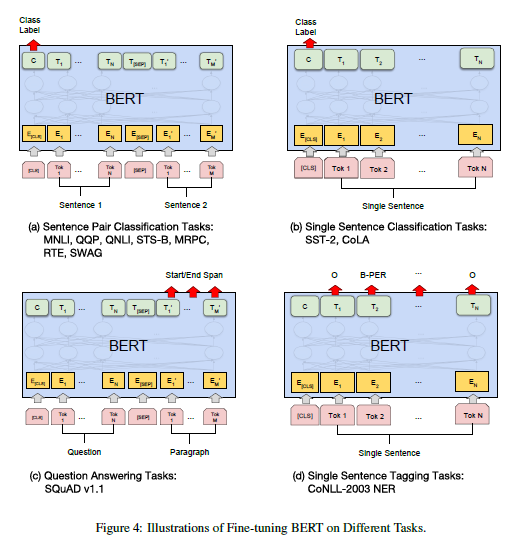
downstream task의 종류에 따라 input이 조금씩 달라지는데, 대표적인 downstream별 입력데이터는 아래와 같다.
- sentence pairs in paraphrasing
- hypothesis-premise pairs in entailment
- question-passage pairs in question answering
- degenerate text pair in text classification or sequence tagging
출처:
[1] nlp-bert-transformer
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[3] Velog, Downstream task란?