8. 딥러닝
26 Nov 2020딥러닝은 계층을 깊게 한 심층신경망이다.
딥러닝의 정확도 향상에 기여하는 것을로는 앙상블 모델 사용, 학습률 감소, 데이터 확장 등이 있다.
이 중 데이터 확장은 입력 이미지를 인위적으로 확장해서 데이터를 늘리는 방법인데, 회전이나 이동, 자르기, 반전, 밝기 변화, 스케일 변화 등이 해당한다. (이 중 반전의 경우 이미지의 대칭성을 고려하지 않는 task에서만 사용된다.)
층을 깊게 하는 이유에 대한 이론적인 근거가 있는 것은 아니지만 대규모 이미지 인식 대회 결과를 보면 상위 모델들이 모두 딥러닝이고 신경망을 더 깊이 쌓는 경향도 있다.
또한 층을 깊이 하면 매개변수의 갯수가 적어지는데, 다시 말해 더 적은 매개변수로 같은 수준의 표현력을 얻을 수 있다.
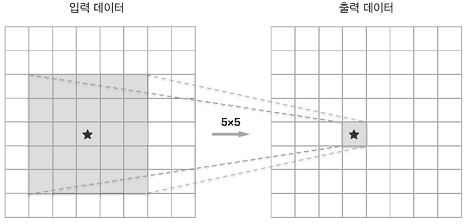
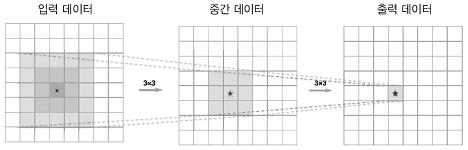
작은 필터를 여러변 겹쳐 신경망을 깊게 하면 적은 매개변수로 더 넓은 수용 영역을 처리할 수 있고, 층마다 ReLU등의 활성화 함수 사용으로 표현력이 더 좋아진다.
층을 깊게하면 효율도 더 좋은데, 더 적은 학습 데이터로 더 빠르게 학습할 수 있다고 한다.
예를 들어서 개를 인식한다고 하면 얕은 신경망은 한번에 많은 특징을 이해해야 해서 더 많은 데이터를 대상으로 더 많이 학습해야 하지만 깊은 신경망은 학습할 내용을 계층적으로 분해해서 각 층이 학습해야 할 문제를 풀기 쉬운 간단한 문제로 쪼갤 수 있다.
이미지넷은 100만장이 넘는 이미지를 담고 있는 데이터셋이고, 각 데이터는 이미지와 레이블 쌍으로 이루어져 있다.
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)라고 이미지 인식 기술을 겨루는 대회가 있는데, 2012년 AlexNet이 등장해서 엄청난 성능으로 주목을 받았다. 이후 딥러닝이 다시 흥하기 시작했는데, 시험항목 중 분류(classification)에서 2012년 이후 항상 선두가 딥러닝 모델이었고, 2015년 나온 ResNet이라는 모델은 인간의 인식 능력을 넘어설 정도였다.
VGG는 구성이 간단한 기본적인 CNN 구조지만 계층이 16층(또는 19층)인 모델이다.
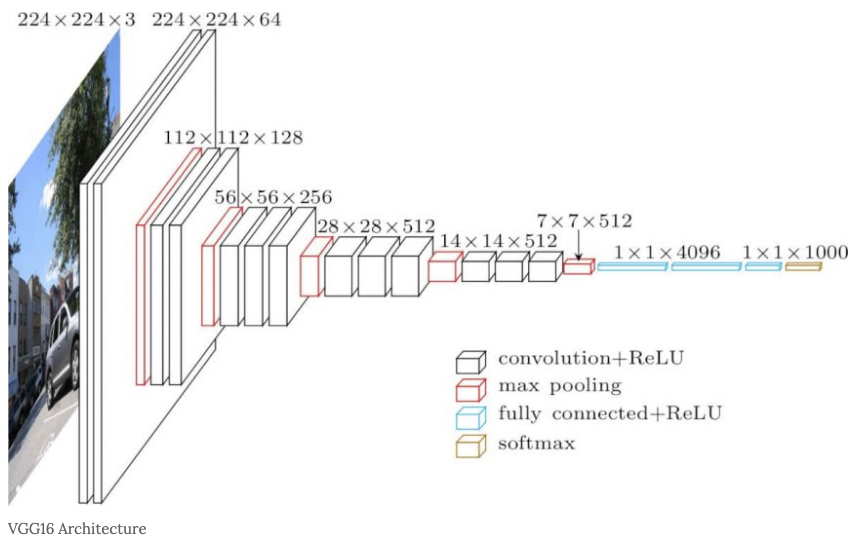
3x3의 작은 필터를 사용한 합성곱 계층을 연속으로 거치고, 2~4회 연속으로 풀링 계층을 사용해서 크기를 절반씩 줄이고, 마지막에는 완전연결계층을 통과해서 결과를 출력한다.
GoogLeNet은 인셉션 구조라는 것을 사용하는데 인셉션 구조에서는 크기가 다른 필터와 풀링을 적용한 결과를 결합해서 사용한다.
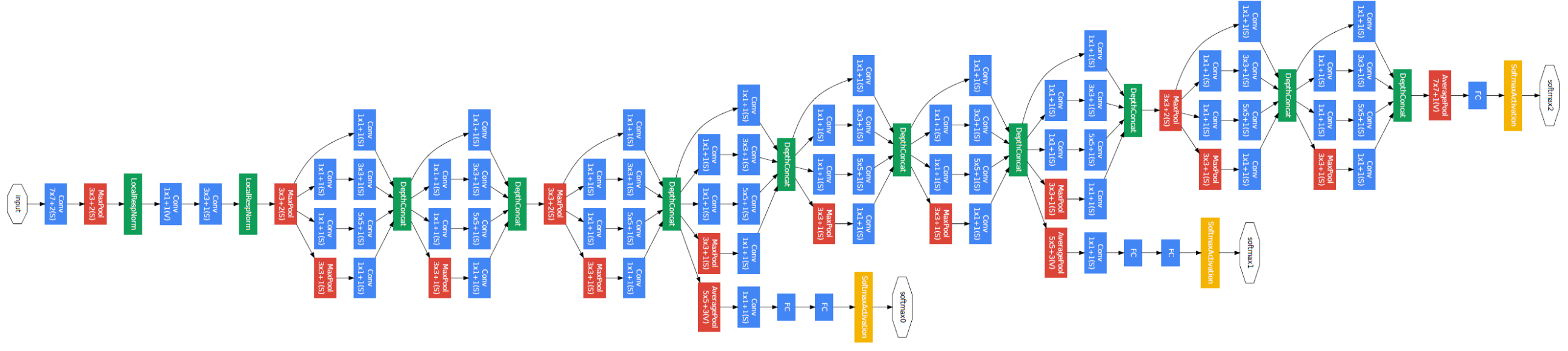
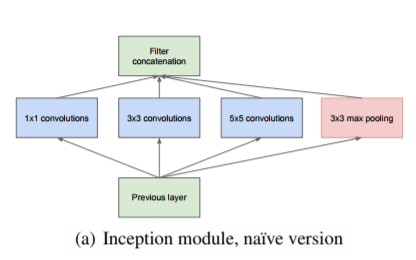
또한 1x1 크기의 필터를 사용하는데, 이를 통해 채널쪽 크기를 줄일 수 있다고 한다.(이 부분은 잘 이해가 안된다)
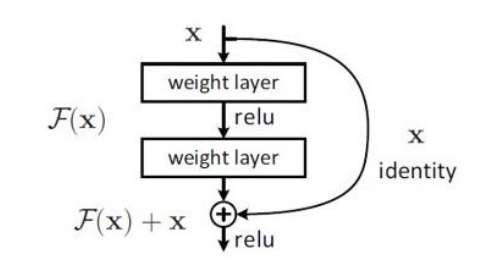
ResNet은 마이크로소프트 팀이 개발한 네트워크로 스킵연결기법을 사용해서 층의 깊이에 비례해 성능을 향상시킨다.

스킵연결을 사용하면 역전파시 신호감쇠를 막아주기 때문에 더 효율적으로 학습이 가능하고 기울기 소실 문제를 완화할 수 있다.
전이학습은 미리 학습된 가중치를 초기값으로 새로운 데이터셋에 재학습을 시키는 방법이다.
딥러닝 연산은 CPU로 부족한데, 주로 GPU와 분산처리를 활용한다.
딥러닝은 학습하는 것이 매우 오래 걸리기 때문에 연산을 어떻게 고속으로 효율적으로 하는지가 중요한데, 딥러닝은 큰 행렬의 곱을 수행해야 하기 때문에 대량병렬 연산을 GPU를 통해 쉽게 구현이 가능하다. (클컴 수업에서 배웠는데 행렬의 곱은 병렬로 수행하기에 용이하다.)
GPU는 주로 엔비디아나 AMD 제품을 사용하는데 CUDA는 엔비디아 그래픽카드 기반이다.
GPU 수가 늘어날 수록 학습도 빨라진다.
메모리 용량과 버스 대역폭도 딥러닝 고속화에 영향을 미치는데 네트워크로 주고받는 데이터의 비트 수를 최소화 하는 것이 좋다.
부동소수점을 비트로 표현하는데, 비트를 많이 쓸수록 오차가 줄어든다. 하지만 딥러닝에서는 오차가 좀 있어도 출력 결과가 크게 달라지지 않기 때문에 주로 16비트 반정밀도 방식을 사용한다고 한다.
비트를 줄이는 것은 딥러닝 고속화, 그리고 딥러닝을 임베디드로 사용하는데에 중요한 영향을 끼친다.
딥러닝은 사물인식 말고도 사물검출, 분할, 사진 캡션 생성 등에도 사용된다.
저자가 꼽은 딥러닝의 미래로 연구될 분야로 이미지 스타일 (화풍) 변환, 이미지 생성, 자율주행, 그리고 강화학습이 있었는데, 앞 두개는 사실 2020년 현재 이미 매우 뛰어난 결과를 보이고 있다고 생각된다. 참고로 강화학습에서는 DQN(Deep Q-Network) 모델을 많이 사용하는데, 게임 분야에서도 강화학습이 많이 사용되어서 Atari, 팩맨등의 게임을 학습할 수 있다고 한다.